Neste artigo
Casa de ferreiro, espeto de pau (e como eu resolvi isso no meu próprio site)
Por anos recomendei arquitetura limpa enquanto o meu próprio site tinha lógica de negócio no model e strings hardcoded no observer. Esse artigo conta como refatorei o mktcode.digital para DDD tático com Domain, Application e Infrastructure — e como conduzi essa refatoração em simbiose com Claude e GPT.

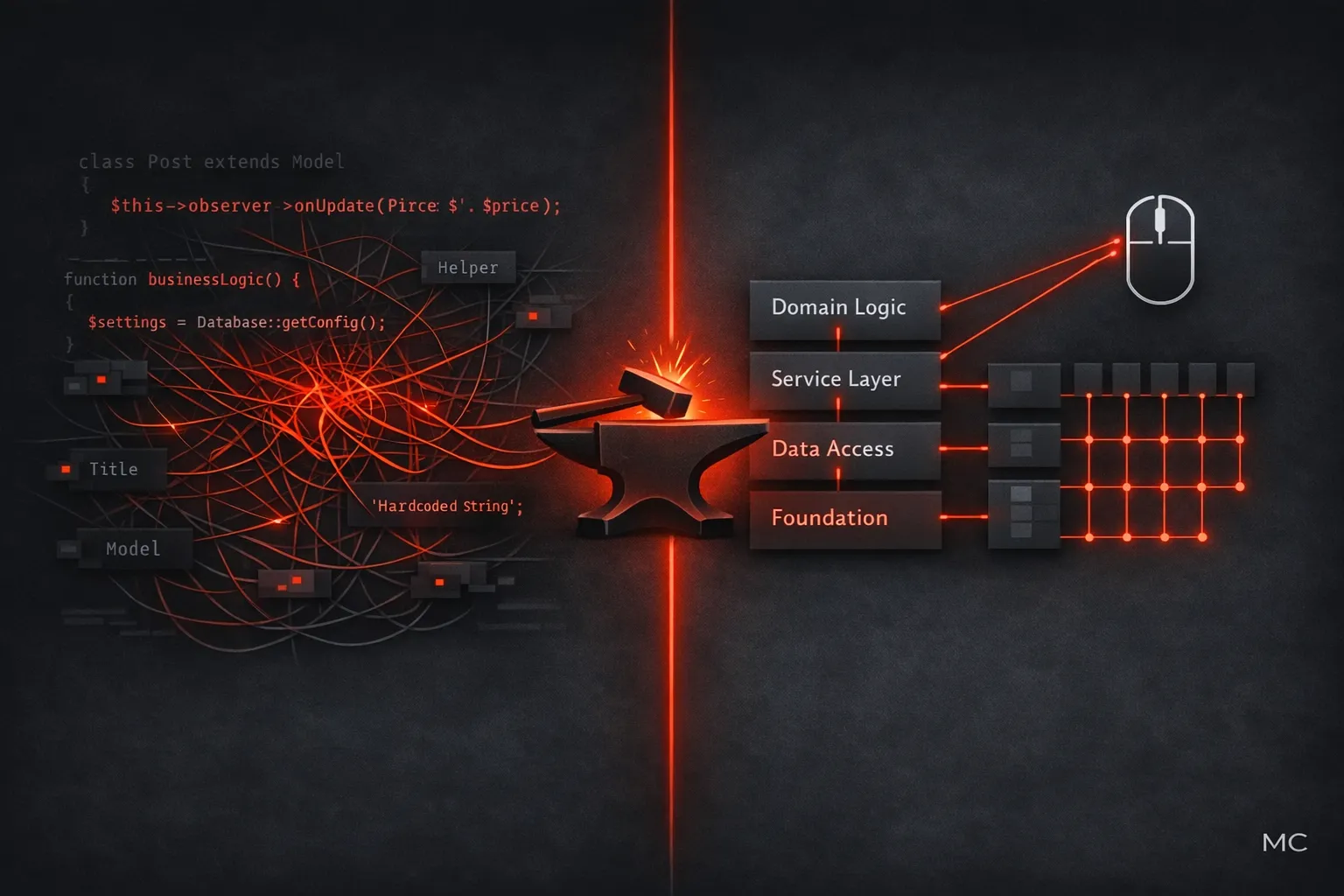
Tem uma frase que eu uso bastante.
Quando o código começa a crescer de forma errada — regra de negócio dentro do controller, query com lógica de visibilidade espalhada pelo model, observer chamando Artisan com string hardcoded — eu digo: isso funciona hoje, mas você vai pagar essa conta com juros.
O problema é que durante um bom tempo, eu disse isso para os outros e aceitei exatamente isso no meu próprio site.
Esse artigo conta como eu percebi isso, o que fiz, e — talvez a parte mais honesta — como eu conduzi essa refatoração junto com duas IAs que hoje fazem parte do meu fluxo de trabalho real: Claude Opus 4.6 e GPT-5.4.
O plano original era simples
Esse novo site mktcode.digital nasceu em janeiro de 2026 com uma proposta direta: site institucional, portfolio, blog, formulário de contato.
Não era pra ser complexo. Era pra ser rápido. Eu tinha dois projetos grandes em produção — o CIM Base e o Omniaflow — e o site da própria MC ficava para as sobras de energia e tempo.
Então eu fiz o que qualquer desenvolvedor faz quando está construindo algo "só pra si mesmo": cortei atalhos que jamais aceitaria em um projeto de cliente.
Os projetos ficavam públicos ou não com Project::public()->ordered() chamado diretamente no controller. A autenticação decidia se o usuário era admin com $user->hasRole(['super_admin', 'admin', 'editor']) embutido na LoginResponse, sem nenhuma camada de indireção. O observer disparava sitemap com Artisan::queue('app:generate-sitemap') — uma string literal, sem contrato, sem constante, sem nada que reclamasse se alguém um dia renomeasse o comando.
Funcionava. O site rodava em produção. Os dados apareciam certos.
Mas eu estava fazendo exatamente o que digo para não fazer.
A contradição que ficou difícil de ignorar
Não foi um momento único. Foi uma acumulação.
Publiquei um artigo sobre Fat Controllers. Quando eu abri o PostController do próprio site, encontrei lógica de visibilidade de post dentro do controller e dentro do model ao mesmo tempo, aplicada em lugares diferentes, com critérios ligeiramente distintos.
Publiquei um artigo sobre Gateway Pattern e o valor de não acoplar lógica de negócio a APIs externas. A implementação de SEO do site resolvia qual Builder usar por manipulação de string de namespace — str_replace('App\\Models\\', 'App\\SEO\\Builders\\', get_class($model)) — uma convenção implícita que falharia silenciosamente em produção se alguém criasse um tipo de conteúdo novo sem seguir exatamente o padrão esperado.
O model Inquiry tinha métodos estáticos que calculavam taxa de resolução, SLA, tempo médio de resposta, e formatavam esses dados para widgets do Filament. Um model de persistência sabia calcular porcentagem e devolver dados prontos para componente de UI. Era o oposto do que eu recomendava.
A ironia era grande demais para aceitar como "mas é só o meu site".
A bifurcação
Existe uma escolha que qualquer desenvolvedor enfrenta num momento assim.
Opção 1: aceitar que projeto pessoal não precisa de arquitetura real e seguir em frente. Muita gente faz isso. É defensável. O site funciona, os clientes não sabem a diferença, o tempo gasto em refatoração poderia ir para features novas.
Opção 2: usar o projeto como campo de validação real — demonstrar que os padrões que você recomenda funcionam também quando você é o cliente, quando o prazo é seu, quando o custo é seu.
Escolhi a opção 2. Não por purismo técnico. Por uma razão prática que ficou cada vez mais clara: se eu não consigo aplicar DDD tático e princípios SOLID em um projeto que controlo completamente — sem cliente, sem prazo externo, sem requisitos mudando toda semana — o que exatamente estou vendendo para os outros?
A credibilidade que construí com o CIM Base e com o Omniaflow vem de ter feito em projetos reais, com problemas reais, e de poder apontar para código em produção quando explico uma decisão. O site da MC não podia ser a exceção à regra.
A metodologia: arquiteto, engenheiro e fiscal
Aqui é onde o processo fica diferente do que a maioria imagina quando ouve "refatorei com IA".
Eu não sento, digito "refatora esse projeto pra DDD" e aceito o que sai. Isso geraria código tecnicamente correto na superfície e arquiteturalmente inconsistente em profundidade — porque a IA não tem contexto do negócio, não tem a história das decisões, não sabe o que é trade-off deliberado e o que é dívida técnica.
O que eu faço — e o que funcionou nesse projeto — é dividir os papéis com clareza.
Eu sou o arquiteto. As decisões de estrutura são minhas: onde fica o Domain, o que vai para Application, o que é responsabilidade da Infrastructure, onde o Filament pode e onde não pode saber de lógica de negócio. Essas decisões não são delegadas. Elas vêm de anos construindo sistemas que cresceram e de ter pago o custo de decisões erradas.
Eu sou o engenheiro. Reviso cada linha antes de ir para o repositório. Entendo o que está sendo gerado. Sei identificar quando a IA produziu código que compila mas que viola um contrato arquitetural. Sei quando o teste está passando pela razão certa e quando está passando por acidente.
Eu sou o fiscal. Defino as regras, garanto que as regras estão sendo seguidas, e corrijo quando saem do trilho. Os testes de arquitetura que foram adicionados ao projeto — que verificam se o Domain importou Filament, se um widget usou app(), se o namespace legado ainda aparece em algum arquivo — existem porque eu pensei nessas invariantes e decidi que elas precisavam ser automatizadas.
Com esse papel claro, a IA entra como a peça que ela realmente é: uma ferramenta de execução extraordinariamente capaz, que multiplica o que um profissional de referência consegue fazer sozinho.
O papel do Claude Opus 4.6 e do GPT-5.4
Duas IAs foram parte ativa dessa refatoração, e é honesto dizer isso.
Passei horas discutindo arquitetura com o Claude Opus 4.6 antes de escrever uma linha nova. Não "me mostra como implementar DDD em Laravel". Discussões reais: como o PanelAccessBridge deveria funcionar dado que o contrato do FilamentUser não permite injeção de dependência direta no canAccessPanel. Como modelar o InquiryStatusView sem vazar lógica de apresentação para o Domain. Se fazia sentido ter PostVisibilityPolicy no Domain ou se era responsabilidade da Infrastructure. O Claude questionou algumas das minhas premissas, propôs alternativas que eu rejeitei com justificativa, e em alguns casos me convenceu a mudar a abordagem.
O GPT-5.4 entrou com força no planejamento de testes. Discutimos quais invariantes arquiteturais deveriam ser testadas — não apenas "os dados aparecem certos", mas "o Domain não importou Filament", "os widgets não usam service locator", "o namespace legado foi completamente removido". Esses testes de arquitetura não são triviais de planejar porque você precisa saber o que proteger antes de saber como proteger.
Depois do planejamento, a execução foi colaborativa: eu fornecia o contexto e os contratos, as IAs geravam implementações, eu revisava e aprovava ou rejeitava com correções específicas. Nenhum bloco de código foi ao repositório sem passar pelos meus olhos e pelo meu entendimento.
O resultado foi 82 testes passando, 0 falhando, 319 assertions — produzidos num ritmo que sozinho levaria o dobro do tempo.
Mas — e isso é o ponto central — a qualidade desse resultado não vem da IA. Vem do profissional que sabe o que pedir, sabe avaliar o que recebe, e sabe o que está faltando mesmo quando o código parece correto.
A IA entrega o que você pede. Se você não sabe o que pedir com precisão, ela entrega algo que parece funcionar. E às vezes até funciona — até o sistema crescer e a decisão arquitetural ruim virar um problema que ninguém sabe resolver porque ninguém entendeu por que aquele código foi escrito.
A primeira onda: estabilização e desacoplamento do Inquiry
A refatoração aconteceu em duas ondas bem definidas. O sistema permaneceu funcional a cada passo — sem reescrita total, sem downtime, sem "para tudo até a refatoração acabar".
A primeira onda foi cirúrgica. Antes de pensar em estrutura maior, corrigi problemas concretos que eram erros, não escolhas.
O problema do status como string. O status de um inquiry era comparado como string em três lugares diferentes — $record->status === 'new', $record->update(['status' => 'in_progress']), $record->status !== 'resolved'. Se o valor do enum mudasse, três comportamentos quebravam silenciosamente. Nenhum erro de compilação. Nenhum teste falhando. Apenas comportamento errado em produção quando alguém abrisse o painel de inquiries.
A correção foi substituir todas as comparações por InquiryStatus::New, InquiryStatus::InProgress, InquiryStatus::Resolved. Parece pequeno. É a diferença entre um contrato explícito e uma convenção implícita que você descobre que quebrou pelo comportamento errado.
O problema do comando como string literal. Os observers de Post, Project e User disparavam o sitemap com Artisan::queue('app:generate-sitemap'). Uma string. Se o comando fosse renomeado, os observers continuariam executando sem erro — mas o sitemap pararia de atualizar. A solução foi GenerateSitemap::SIGNATURE, uma constante. Se a constante mudar, todos os usos atualizam juntos. Se o arquivo for removido, o compilador avisa.
O problema do model que sabia calcular SLA. O model Inquiry tinha getDashboardCounts(), getAvgResponseTime(), getActivityChartData() — métodos estáticos que faziam queries analíticas, calculavam taxas de porcentagem e devolviam dados formatados para componentes de UI do Filament. Tudo isso foi para InquiryMetricsQuery e InquiryActivityChartQuery, objetos dedicados com responsabilidade única.
O SeoResolver original usava str_replace de namespace para descobrir qual Builder chamar. Isso foi substituído por um match explícito — Post chama PostSeoBuilder, Project chama ProjectSeoBuilder, User chama UserSeoBuilder. Cada caso declarado, nenhuma convenção implícita que falha silenciosamente quando você cria um tipo de conteúdo novo sem saber que existia esse padrão.
Ao final da primeira onda, o sistema estava mais honesto consigo mesmo. Contratos explícitos onde havia strings. Queries com responsabilidade única onde havia métodos estáticos analíticos em model. Testes cobrindo os novos comportamentos.
A segunda onda: a arquitetura de verdade
Aqui é onde o projeto mudou de categoria.
O Domain passou a existir como camada real.
Os enums foram movidos de app/Enums/ para Domain/Content/Enums/, Domain/Inquiry/Enums/, Domain/Portfolio/Enums/. E nessa mudança aconteceu algo importante: eles perderam implements HasColor, HasLabel do Filament.
Isso não é detalhe estético. É uma decisão arquitetural: o domínio não conhece Filament. PostStatus no Domain é um enum de negócio. Ele não sabe que existe uma cor "warning" ou um label "Rascunho" para mostrar no painel admin. Quem sabe disso é o InquiryStatusView na camada Application — um objeto de apresentação que traduz o enum de domínio para o que o Filament precisa exibir.
Foram criados contratos de repositório: PostRepository, ProjectRepository, InquiryRepository, UserRepository. O Domain declara o que precisa. A Infrastructure entrega. O Eloquent fica contido e não vaza para os casos de uso, não aparece nos testes de domínio.
A Application Layer ganhou estrutura real por contexto.
Não uma pasta genérica Services. Casos de uso nomeados com intenção:
Application/Content/Commands/PublishPost
Application/Content/Commands/SchedulePost
Application/Content/Commands/UnpublishPost
Application/Portfolio/Commands/AssignProjectOwner
Application/Portfolio/Commands/FeatureProject
Application/Inquiry/Commands/MarkInquiryInProgress
Application/Inquiry/Commands/ResolveInquiry
Application/Identity/Services/AdminAccessDeciderCada nome declara o que acontece. Nenhuma ambiguidade. Quando você abre o projeto pela primeira vez e quer entender o que acontece quando um post é publicado, você vai em PublishPost. Não precisa ler o controller, não precisa caçar o model, não precisa descobrir se a lógica está no observer ou na action.
Os DTOs apareceram como cidadãos de primeira classe. SubmitInquiryData com campos tipados em vez de array{name: string, email: string, message: string} espalhado em cinco lugares. PostPublicationData que encapsula status e data de publicação e tem um fromArray() que converte o que vem do formulário Filament. PublicPostViewData e PublicProjectViewData que serializam o que o frontend precisa, sem expor o Eloquent model diretamente para a camada de apresentação.
Os controllers públicos ficaram com uma única responsabilidade.
Antes, um controller de show de post fazia: verificar se o post é publicamente visível, carregar relacionamentos com load(), serializar com resource, gerar SEO, renderizar. Quatro responsabilidades no mesmo método.
Depois:
public function show(
string $post,
GetPublicPostQuery $getPublicPost,
SeoService $seo
): Response
{
$resolvedPost = $getPublicPost->findBySlug($post);
if ($resolvedPost === null) {
throw new NotFoundHttpException;
}
return Inertia::render('public/blog/Show', [
'post' => PublicPostShowResource::make(PublicPostViewData::detail($resolvedPost))->resolve(),
'seo' => $seo->forPost($resolvedPost),
]);
}O controller recebe a requisição. Chama a query — que internamente sabe quais relacionamentos carregar e qual política de visibilidade aplicar. Renderiza o resultado. Sem query Eloquent. Sem verificação de status. Sem lógica de carregamento de relacionamentos. Sem SEO sendo gerado inline.
Quem quer entender a regra de visibilidade vai em PostVisibilityPolicy no Domain. Quem quer entender o que é carregado vai em EloquentPostRepository. Quem quer entender a serialização vai em PublicPostViewData. Separação real, não separação cosmética.
O Filament virou adapter.
Essa foi uma das mudanças mais significativas para a qualidade do código de longo prazo.
Criar um post no Filament antes invocava o Eloquent diretamente. Publicar um projeto atualizava campos no model sem nenhuma camada intermediária. Actions do InquiryResource chamavam $record->update(['status' => InquiryStatus::Resolved]) diretamente.
Depois, o CreatePost do Filament sobrescreve handleRecordCreation e aciona PostPublicationWorkflow. O EditProject aciona ProjectAdministrativeWorkflow. As actions do InquiryResource chamam MarkInquiryInProgress e ResolveInquiry — Commands da Application Layer.
O Filament não decide nada. Ele coleta dados do formulário, chama o caso de uso correto, e exibe o resultado. Se amanhã eu quiser adicionar uma validação de negócio antes de publicar um post — "post só pode ser publicado se tiver categoria e thumbnail" — esse código vai em um único lugar na Application Layer. O Filament não muda. O controller público não muda. O teste que valida essa regra testa o Command, não a UI.
O SEO que finalmente faz sentido
SEO merece uma seção separada porque era o ponto com o problema mais sutil e potencialmente mais danoso.
O SeoResolver original era elegante na superfície. Você implementava HasSeo no model, criava um Builder com o nome certo, e o Resolver descobria o Builder automaticamente por convenção de namespace. Parecia OCP — aberto para extensão, fechado para modificação.
O problema estava na falha silenciosa. Se o Builder não existisse com o nome exato esperado, o class_exists() retornava false, o throw_if disparava — mas só em runtime, só quando alguém tentasse abrir aquela página específica, só se aquele código fosse executado. Em desenvolvimento você podia trabalhar semanas sem saber que o Builder de um tipo de conteúdo novo estava faltando.
O novo SeoRegistry é explícito por design. Cada Builder declara via supports() quais objetos sabe processar. O registro sabe quais builders existem porque eles são registrados no SeoServiceProvider:
$this->app->singleton(SeoRegistry::class, function ($app): SeoRegistry {
return new SeoRegistry([
$app->make(PostSeoBuilder::class),
$app->make(ProjectSeoBuilder::class),
$app->make(UserSeoBuilder::class),
]);
});Se eu criar um novo tipo de conteúdo e esquecer de registrar o Builder, o SeoRegistry lança InvalidArgumentException imediatamente quando o código tenta resolver SEO para aquele tipo. Não em produção com meta tag vazia. Em desenvolvimento, na primeira vez que a rota é acessada.
Os Builders migraram para Infrastructure/Shared/SEO/Builders/ e passaram a implementar o contrato SeoDataBuilder do Domain. O SeoData — antes em app/SEO/DTO/SeoData.php — migrou para Application/Shared/DTOs/SeoData.php, onde conceitualmente pertence: é um DTO de output que trafega da Infrastructure para o frontend via controller.
O SeoService ficou mais simples porque passou a delegar para o Registry:
public function forPost(Post $post): SeoData
{
return $this->registry->build($post);
}O controller chama $seo->forPost($post). O Service chama o Registry. O Registry encontra o PostSeoBuilder. O Builder gera o SeoData. O frontend recebe os dados prontos. Nenhuma string de namespace sendo manipulada. Nenhuma convenção implícita.
Os testes como documentação arquitetural
Ao final das duas ondas, 82 testes passando. Mas o número não é o ponto mais importante.
O ponto mais importante é o que está sendo testado.
Os testes de feature validam os comportamentos visíveis: draft posts retornam 404, posts agendados retornam 404 antes da data, projetos draft retornam 404, perfil público só expõe posts publicados, homepage ordena projetos por featured e sort_order, formulário de contato persiste e notifica.
Os testes de arquitetura validam as invariantes estruturais:
Domain não importa Filament\
Domain não importa Illuminate\Http
Domain não usa app()
Application não importa Filament
Widgets não usam app() ou resolve()
Recursos não usam app() ou resolve()
Namespace App\Enums\ não existe mais em nenhum arquivo
Namespace App\Application\Inquiries\ não existe mais
Queries terminam em Query
Commands têm nome imperativo
Models não expõem métodos de apresentação (getStatusLabel, getStatusColor)
Esses testes não verificam comportamento para o usuário. Eles verificam que as regras arquiteturais estão sendo cumpridas — e continuarão sendo cumpridas quando alguém (eu, daqui a seis meses, com contexto diferente) adicionar código novo.
Arquitetura sem guardrails automatizados é documentação que envelhece. Com esses testes, qualquer violação da estrutura quebra a build. A arquitetura se auto-documenta e se auto-valida.
O que a IA faz bem e o que ela não substitui
Depois de meses trabalhando nesse projeto em simbiose com Claude e GPT, tenho uma visão mais clara do que isso significa na prática.
A IA executa com uma velocidade e consistência que nenhum desenvolvedor humano atinge. Dado um contrato bem definido — "implemente EloquentInquiryRepository conforme essa interface, usando estas queries, com compatibilidade SQLite e MySQL" — o resultado é preciso, completo e correto na primeira tentativa na maioria das vezes.
A IA não se cansa. Não comete erros de digitação às 23h. Não esquece de adicionar declare(strict_types=1). Não deixa um var_dump esquecido. Não acha que "funciona" é sinônimo de "está certo".
Mas a IA não tem julgamento arquitetural. Ela não sabe, por conta própria, que colocar HasColor e HasLabel do Filament em um enum do Domain é um problema — porque ela não tem a experiência de ter mantido sistemas que cresceram e onde essas dependências cruzadas se tornaram dívidas. Ela não sabe que um SeoResolver baseado em convenção de namespace vai falhar silenciosamente em produção — porque ela não viveu a diferença entre um sistema que falha ruidosamente em desenvolvimento e um que falha silenciosamente em produção.
Ela entrega o que você pede. A qualidade do que ela entrega é proporcional à qualidade do que você pede — e saber o que pedir, com precisão, com contexto, com as restrições certas, é exatamente o que diferencia um desenvolvedor sênior de alguém que ainda está aprendendo.
Esse projeto não teria sido possível no mesmo tempo sem IA. Também não teria a qualidade que tem se eu tivesse simplesmente delegado as decisões para ela.
Eu fui o arquiteto, o engenheiro e o fiscal dessa obra. A IA foi o executor mais capaz que já tive à disposição.
O que ficou diferente no projeto
Antes da refatoração, o mktcode.digital era um site Laravel bem feito pelo padrão de mercado. Controllers razoáveis, models com algum inchaço, SEO funcional mas acoplado, testes de comportamento básicos.
Depois, é um projeto onde eu consigo responder com precisão qualquer pergunta sobre onde fica cada responsabilidade.
Onde fica a regra de negócio de visibilidade de um post? PostVisibilityPolicy no Domain.
Quem decide se um usuário pode acessar o painel admin? AdminAccessDecider na Application Layer, invocado pelo PanelAccessBridge que conecta o contrato do Filament com a lógica de domínio sem que o model User precise conhecer a Application Layer diretamente.
Como é adicionado um novo tipo de conteúdo com SEO próprio? Cria-se um Builder que implementa SeoDataBuilder, registra no SeoServiceProvider, e o sistema inteiro passa a suportar o novo tipo. Nenhum arquivo existente muda. Nenhum mapeamento manual.
O que acontece quando um post é publicado? PostPublicationWorkflow aciona PublishPost ou SchedulePost dependendo da data, o observer detecta a mudança e aciona QueueSitemapGeneration, o sitemap é regenerado assincronamente.
Qual a diferença prática para quem usa o site? Nenhuma visível. O site funciona igual.
A diferença é para quem mantém — que nesse caso sou eu, e que daqui a um ano ainda precisarei entender cada decisão sem reler todo o código do zero.
A parte irônica
Esse projeto começou como "só um site institucional". Virou a base de validação de tudo que eu aplico em sistemas de clientes.
O Omniaflow processa cobranças reais de dezenas de franquias com arquitetura event-driven, Gateway Pattern para integração com Asaas, multitenancy por design. O CIM Base tem DDD tático com RBAC granular, 50 componentes de UI compartilhados, site e CRM integrados no mesmo monolito. Ambos em produção há meses.
O mktcode.digital é um portfolio e um blog. Mas agora tem a mesma estrutura — Domain, Application, Infrastructure, Interfaces — os mesmos guardrails automatizados, a mesma capacidade de responder com precisão onde fica cada responsabilidade.
E foi construído em simbiose com IAs que não existiam quando eu comecei a programar. IAs que eu direcionei, questionei, avaliei e às vezes corrigi. Que me fizeram pensar mais rápido, executar com mais consistência, e validar decisões que de outra forma levariam dias.
Quando alguém me perguntar "como você estruturaria um projeto do zero?", a resposta não vai ser teórica. Vai ser: exatamente como o meu próprio site está estruturado — e eu tenho os commits, os testes e a história das decisões para mostrar.
Casa de ferreiro, espeto de ferro.
Esse post é parte da série de bastidores do mktcode.digital — decisões técnicas reais, sem romantismo. O código está funcionando em produção. Os testes estão passando. As decisões têm razão.
Está construindo algo que precisa de arquitetura que não envelhece? Fala comigo.